Visualising API Structure with OpenAPI Visualiser
My OpenAPI Visualiser project has had a modernisation update and reached 1.x. What is it, and what is new?
My OpenAPI Visualiser project has had a modernisation update and reached 1.x. What is it, and what is new?
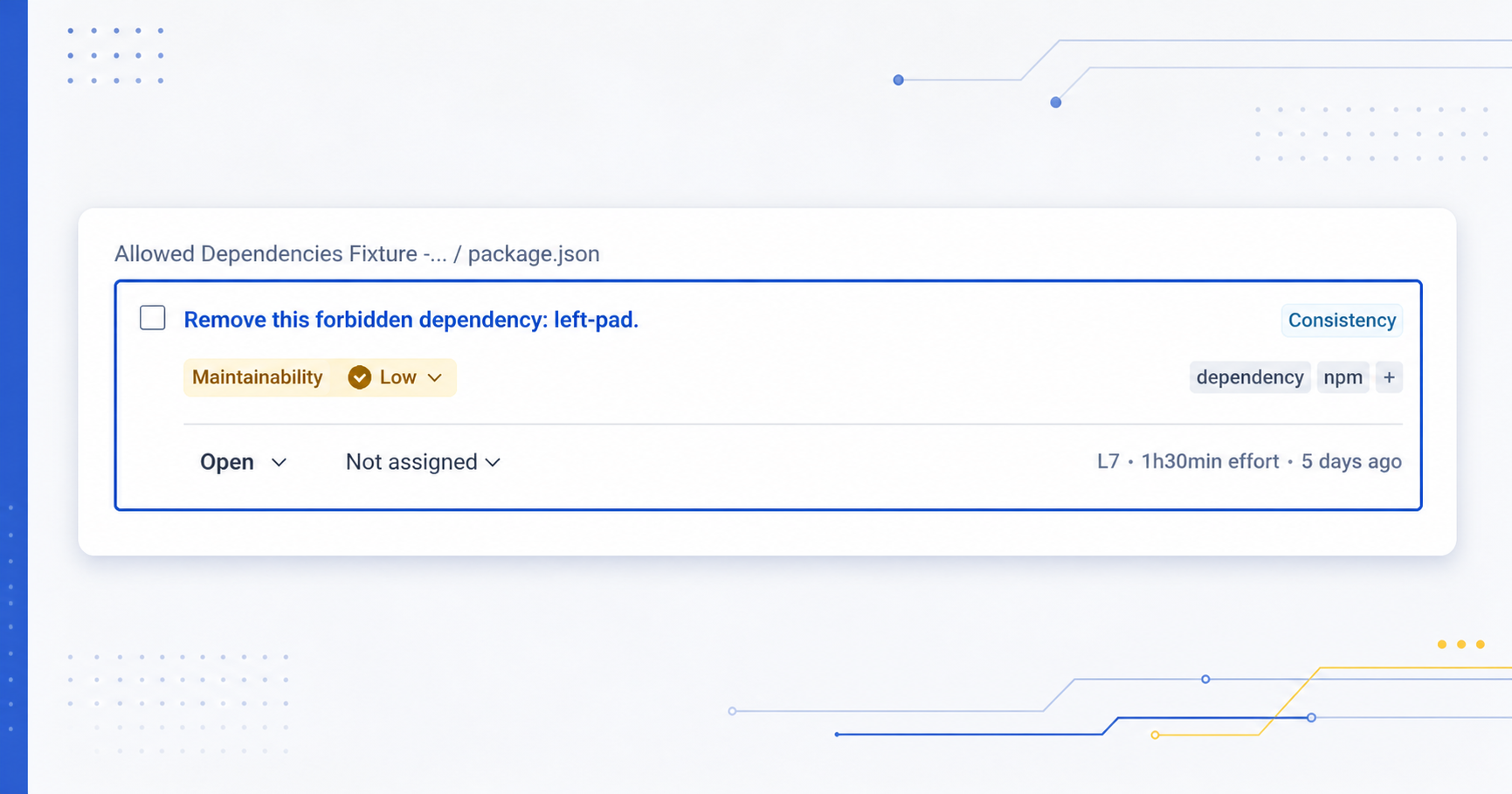
My plugin for enforcing that project dependencies match an approval list has reached a 1.0 milestone.
The time for developing my own blog CSS from scratch has come to an end - I’ve switched to the Chirpy theme.
Rather than pulling a new Ethernet cable, I’m temporarily routing my WAN connection across two switches using a dedicated VLAN (setting up WAN-over-VLAN).
Continuing on from my last post about Configuration as Code in Jenkins, this goes in to a bit more detail on how I’ve configured ephemeral docker-based Jenkins agents (and the container it runs for my transcoding workflow).